Что такое SQL и зачем он нужен аналитику данных
SQL (Structured Query Language — «структурированный язык запросов») — декларативный язык запросов к реляционным базам данных, международный стандарт ISO/IEC 9075. Аналитик описывает ЧТО получить, а СУБД решает КАК. По данным аналитики рынка труда hh.ru за май 2026 года, SQL входит в топ-3 ИТ-навыков: более 2 800 вакансий аналитика в Москве содержат его как требование. В статье разберём ключевые конструкции языка, объясним оконные функции и типичные ошибки — и покажем, как понять, что освоение SQL для аналитика данных достаточно для первого самостоятельного проекта.

SQL — это язык запросов: расшифровка и суть понятия
SQL расшифровывается как Structured Query Language. Язык стандартизирован документом ISO/IEC 9075 и поддерживается всеми крупными СУБД — системами управления базами данных. Главное свойство — декларативность: аналитик описывает результат, а не алгоритм его получения. Это принципиально отличает SQL от процедурных языков вроде Python или Java — там программист управляет каждым шагом выполнения.

Учитесь бесплатно за счёт государства
Экономия до 100 000 ₽ на любой программе
SQL — не программа. Для работы нужны СУБД, которая принимает и выполняет команды (PostgreSQL, MySQL, ClickHouse и другие), и клиентский инструмент для подключения к базе: DBeaver (бесплатный кроссплатформенный клиент) или DataGrip (платный, от JetBrains).
Данные в реляционных базах хранятся в связанных таблицах. У каждой есть первичный ключ (primary key) — уникальный идентификатор строки. Внешний ключ (foreign key) ссылается на первичный ключ другой таблицы и создает связь между ними. Эта структура и позволяет объединять данные через JOIN.
Зачем аналитику данных нужен SQL
Без SQL аналитик зависит от готовых выгрузок разработчика: нужен новый срез — важно подождать. С SQL можно самостоятельно получать данные из базы, объединять таблицы и готовить их для дашборда.
Типовые задачи: выборка клиентов по условию, расчет выручки по каналам, сегментация аудитории, подготовка витрины данных для Power BI. SQL обязателен для BI-аналитика, продуктового и маркетингового аналитика. По данным hh.ru (май 2026), 2 800+ вакансий аналитика в Москве указывают его как ключевое требование. Знание оконных функций — маркер перехода с базового на уверенный уровень.
SQL или Excel: что выбрать и когда
Excel удобен для небольших таблиц, ручного анализа и быстрой проверки срезов. Но возможности ограничены: большой объём данных замедляет файл, повторяемые операции требуют макросов, а объединить несколько источников без SQL сложно.
SQL незаменим, когда данные хранятся в базе, объём измеряется миллионами строк или запрос выполняется регулярно. Инструменты не конкурируют: SQL достаёт и агрегирует данные — Excel быстро строит сводную или проверяет срез.
Сигнал, что пора изучать SQL: вы регулярно запрашиваете у разработчика выгрузки в нужном формате. Как только задача становится повторяющейся — зависимость от готовых выгрузок превращается в постоянный тормоз.
Базовые конструкции SQL: с чего начать
Первый уровень — SELECT / FROM / WHERE / ORDER BY / LIMIT / DISTINCT: выборка строк с фильтрацией и сортировкой. Важны типы данных: INT, VARCHAR, TIMESTAMP, DATE. Несовпадение типов ломает сравнения — частая причина незаметной потери записей в запросе.
80% аналитических задач завязаны на времени: EXTRACT и DATE_TRUNC помогают работать с датами. Условная логика CASE WHEN / THEN / ELSE позволяет размечать данные и создавать категории прямо в запросе.
Агрегатные функции и GROUP BY: считаем метрики по категориям
Агрегатные функции — основа любого аналитического расчета: COUNT считает строки, SUM суммирует значения, AVG вычисляет среднее, MIN и MAX возвращают крайние значения.
GROUP BY группирует строки по категории: выручка по городам, заявки по каналам привлечения, средний чек по месяцам, клиенты по сегментам. Агрегирование данных происходит внутри каждой такой группы.
Важное различие: WHERE фильтрует строки до группировки, HAVING — после. Путаница здесь меняет результат. Например, фильтр по статусу заказа нужен в WHERE, а отсечение групп с малым объёмом продаж — в HAVING. Смешение двух операторов — частая ошибка при первой работе с данными.
JOIN: как объединять таблицы без дублей
JOIN объединяет таблицы по ключевому полю. Клиенты, заказы и платежи хранятся раздельно — JOIN собирает их вместе по первичному ключу.
Основные виды: INNER JOIN возвращает только совпадающие строки из обеих таблиц; LEFT JOIN — все строки левой таблицы и совпадения из правой (несовпадения заполняются NULL). LEFT JOIN самый частый в аналитике: он сохраняет клиентов без заказов, а не теряет их, как INNER JOIN.
Критическая ошибка: соединение по неверному ключу приводит к декартову произведению — дублям строк. Сумма метрики окажется завышенной, хотя запрос выполнится без ошибок. Правило: после JOIN всегда проверяйте COUNT(*) на соответствие ожидаемому числу строк — это позволяет поймать дубли в данных до построения дашборда.
Продвинутый уровень: оконные функции в SQL
Оконные функции — ключевой дифференциатор между начинающим аналитиком и уверенным специалистом. В отличие от GROUP BY, они вычисляют значение для каждой строки без схлопывания результата в одну строку на группу. Оконные функции не заменяют GROUP BY, а дополняют его: GROUP BY агрегирует данные, оконные функции добавляют контекст к каждой строке [14].
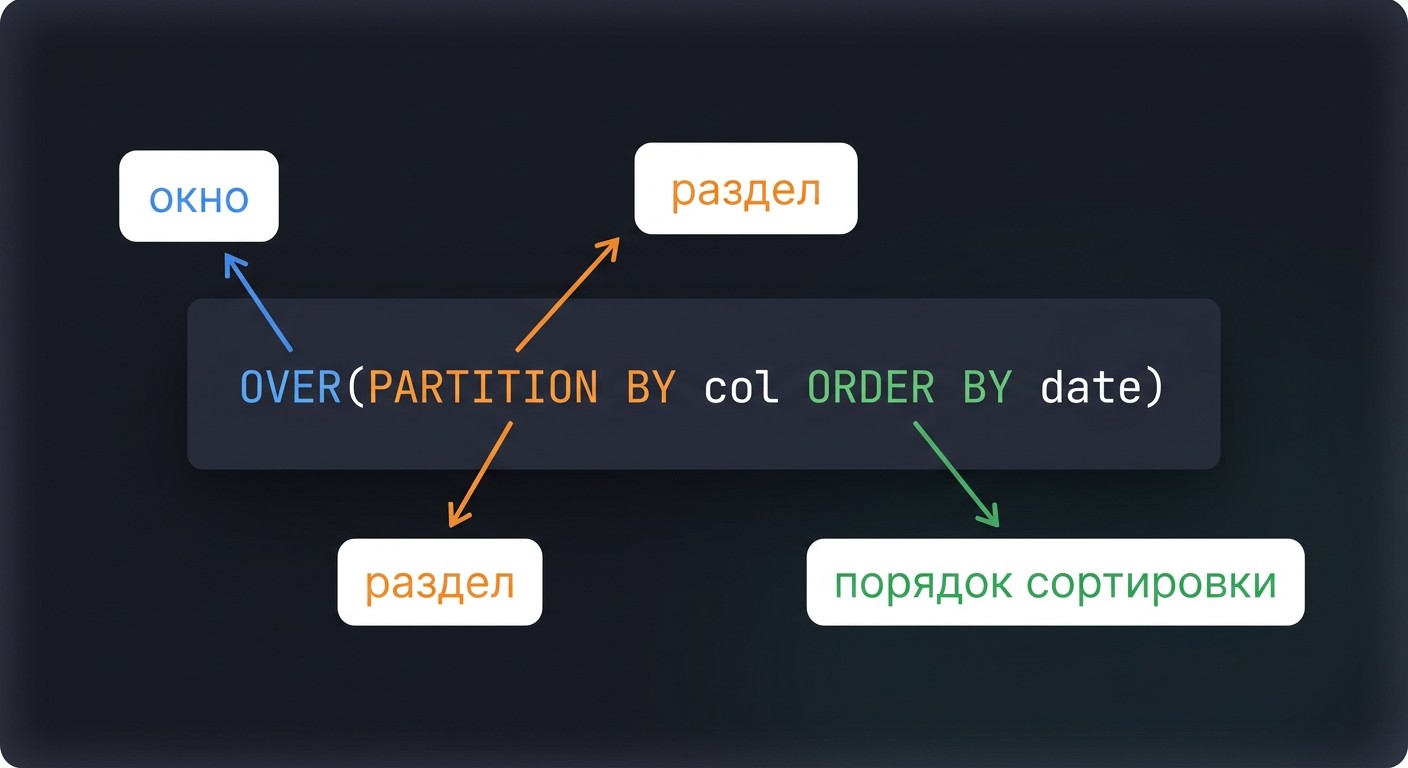
Синтаксис: FUNCTION() OVER(PARTITION BY … ORDER BY …). Три подтипа: ранжирование (ROW_NUMBER, RANK, DENSE_RANK), навигация по строкам (LAG, LEAD) и агрегация с сохранением детализации (SUM OVER, COUNT OVER).
PARTITION BY определяет окно (группу строк), а ORDER BY задает порядок внутри окна — это критично для LAG/LEAD` и ранжирующих функций.
LAG и LEAD: анализируем изменения между периодами
LAG() возвращает значение предыдущей строки в окне: динамика метрики месяц к месяцу, разница между текущим и прошлым платежом. LEAD() смотрит на следующую строку: анализ повторных покупок, прогноз следующей транзакции.
Пример бизнес-задачи: как изменилась выручка по сравнению с предыдущим месяцем? Без LAG нужно самосоединение таблицы — громоздкий и сложный в поддержке подход. С LAG задача решается в одном запросе.
Знание LAG и LEAD — сигнал уверенного уровня: эти функции регулярно встречаются в тестовых заданиях на собеседованиях аналитика данных.
Когортный анализ и Retention через SQL
Когортный анализ отслеживает поведение группы пользователей во времени. Ключевые метрики: Retention (удержание — доля клиентов, вернувшихся после первой покупки) и Churn (отток — доля ушедших). Эти показатели отражают, насколько хорошо продукт удерживает аудиторию.
Реализация: оконные функции + JOIN таблиц заказов и клиентов с временными метками. CTE (Common Table Expression, конструкция WITH…AS) структурирует сложный когортный запрос и избавляет от дублирования подзапросов — код становится читаемым.
Когортный анализ — классическое тестовое задание на собеседовании аналитика и явный маркер продвинутого уровня в описании вакансий.
Какую СУБД выбрать аналитику: PostgreSQL, ClickHouse, BigQuery
Аналитику не нужно администрировать СУБД, но понимать её тип и особенности важно — это влияет на синтаксис и оптимизацию запросов.
| СУБД | Тип | Назначение | Ключевая особенность | Когда выбирать |
|---|---|---|---|---|
| PostgreSQL | Реляционная | Транзакционные данные | Open source, EXPLAIN ANALYZE, оконные функции, CTE, поддержка JSON и геоданных | Старт, учебная среда, рабочие проекты |
| ClickHouse | Колоночная (OLAP) Online Analytical Processing |
Аналитика по большим объёмам Не подходит для OLTP-задач |
MergeTree-движок, высокая скорость агрегации, нет транзакций | Большие данные, BI-отчёты |
| BigQuery | Облачное хранилище (DWH) Data Warehouse |
Аналитика в облаке Google | Оплата за прочитанные байты, партиционирование обязательно | Облачная инфраструктура Google |
Таблица 1. Сравнение СУБД для аналитика данных. Источник: официальная документация PostgreSQL, ClickHouse, BigQuery.
Хотите сменить профессию или повысить квалификацию?
Федеральный проект «Активные меры содействия занятости» даёт возможность пройти обучение бесплатно за счёт государства
- Программы от ведущих вузов России — от 2 месяцев
- Удостоверение или диплом установленного образца
- Центр карьеры: 7 500+ вакансий, помощь с трудоустройством

PostgreSQL рекомендуется для старта: open source (открытый исходный код), полная поддержка стандарта SQL, оконные функции, CTE и EXPLAIN ANALYZE — инструмент для разбора плана запроса. ClickHouse и BigQuery встречаются на реальных проектах — базовый синтаксис переносится, нюансы изучаются по ходу. Аналитику достаточно понимать роль индексов и читать план запроса для оценки производительности запросов.
Типичные ошибки аналитика при работе с SQL

JOIN по неверному ключу. Результат — дубли в данных и завышенная сумма метрики. Запрос выполняется без ошибок, дашборд строится на неверных данных. А неучет NULL‑значений в JOIN» — частая проблема, приводящая к потере данных.
Решение: проверка COUNT(*) после каждого JOIN.
Путаница WHERE и HAVING. WHERE фильтрует до группировки, HAVING — после. Одно и то же условие в разных местах дает разные результаты в расчётах — и оба запроса выглядят корректно.
Несовместимые типы данных. Сравнение TIMESTAMP и DATE без явного приведения типов — часть записей «теряется». Ошибки выполнения нет, но неверный вывод гарантирован.
Синтаксис без понимания задачи. Аналитик знает SELECT и GROUP BY, но не понимает, что именно считает. Обучение без реальных бизнес-задач ведет к ошибкам в расчетах на рабочих данных.
Правило трёх проверок после каждого запроса: COUNT(*) строк совпадает с ожидаемым числом → сумма ключевой метрики выглядит логично → несколько строк вручную соответствуют исходным данным.
Как понять, что базы SQL достаточно для первого проекта

Критерий готовности — самостоятельно получить данные, соединить таблицы, посчитать метрики и объяснить результат бизнесу. Чеклист из пяти умений: SELECT с фильтрами, GROUP BY с агрегатами, JOIN без дублей, оконные функции, проверка результата.
Портфолио: набор связанных таблиц + 10–15 запросов + описание бизнес-задач, метрики и выводы. Работодатель оценивает не только синтаксис, но и интерпретацию данных.
Маршрут дальше: базовый SQL → Power BI или Tableau (инструменты визуализации) → Python (расширенная аналитика). Power BI изучают после SQL: без умения готовить данные можно построить красивый дашборд с неверной логикой.
Освоить SQL с нуля, разобрать реальные аналитические задачи и получить официальный документ об образовании можно по программе «Специалист по аналитике и базам данных в информационных системах» (256 часов, онлайн) — за счёт государственного финансирования. Подробнее в каталоге программ обучения.
Часто задаваемые вопросы
SQL — это язык программирования или программа?
SQL — язык запросов, не программа. Сам по себе он не запускается: нужна СУБД (PostgreSQL, MySQL, ClickHouse), которая принимает SQL-команды и выполняет их, и клиентский инструмент (DBeaver, DataGrip) для подключения к базе. SQL описывает ЧТО получить — СУБД решает КАК.
Что означает аббревиатура SQL и как правильно произносить?
SQL расшифровывается как Structured Query Language — «структурированный язык запросов», международный стандарт ISO/IEC 9075. Произносится «эс-кью-эл» по-английски или «эскюэль» — распространённая русскоязычная версия. Оба варианта корректны в профессиональной среде.
Чем оконные функции отличаются от GROUP BY?
GROUP BY схлопывает строки — на выходе одна строка на группу. Оконные функции вычисляют значение для каждой строки, сохраняя исходную детализацию. Например, SUM() OVER(PARTITION BY город) добавляет сумму продаж по городу к каждой строке заказа, не удаляя строки из результата.
Сколько времени нужно, чтобы выучить SQL с нуля?
Базовый SELECT, фильтры, сортировка — около недели практики. JOIN и GROUP BY с агрегатными функциями — 2–3 недели. Оконные функции и CTE — 4–6 недель. Первый аналитический проект реально собрать за 4–8 недель при регулярных занятиях. Ключевое — работать с реальными бизнес-задачами, не только синтаксическими тренажёрами.
Какие задачи решают SQL-запросы в работе аналитика?
Типовые задачи: выборка нужных строк из базы, соединение таблиц клиентов и заказов, расчёт метрик по категориям, подготовка витрины данных для дашборда, когортный анализ с Retention и Churn. SQL покрывает весь цикл — от получения данных до передачи в BI-инструмент.
Можно ли работать аналитиком без знания SQL?
Можно, но выбор задач будет ограничен: придётся зависеть от готовых выгрузок разработчиков. Для BI-аналитики, продуктовой и маркетинговой аналитики SQL быстро становится обязательным рабочим навыком. По данным hh.ru (май 2026), 2 800+ вакансий аналитика в Москве указывают его как требование.
Какую СУБД выбрать для старта изучения SQL?
Для старта — PostgreSQL: open source, полная поддержка стандарта SQL, оконные функции, CTE, EXPLAIN ANALYZE, широкое применение в учебных и рабочих средах. На реальном проекте познакомитесь с ClickHouse, BigQuery или другой СУБД компании — базовый синтаксис переносится, нюансы изучаются по ходу работы.
Что такое когортный анализ и зачем он нужен аналитику?
Когортный анализ отслеживает поведение группы пользователей во времени: сколько клиентов, сделавших первый заказ в январе, вернулись в феврале (Retention) и сколько ушло (Churn). Реализуется через SQL — оконные функции и JOIN таблиц с временными метками. Классическое тестовое задание на собеседовании аналитика.
Когда стоит переходить к изучению Power BI после SQL?
Power BI изучают после того, как SQL понятен и можно самостоятельно подготовить таблицу с нужными метриками. Без SQL-фундамента легко построить красивый дашборд с неверной логикой данных. Оптимальный маршрут: SELECT → JOIN и агрегация → оконные функции → первый проект → Power BI.
Как проверить правильность SQL-запроса?
Три проверки после каждого запроса: 1) COUNT(*) строк совпадает с ожидаемым числом; 2) сумма ключевой метрики выглядит логично; 3) несколько строк вручную соответствуют исходным данным. Запрос может выполняться без ошибок, но дать неверный результат из-за дублей или неправильного JOIN.
Также важно проверять типы данных в результате (например, даты должны быть в формате DATE, а не VARCHAR) и наличие NULL‑значений, которые могут исказить агрегацию
Хотите освоить SQL и аналитику данных без вложений? В рамках федерального проекта «Активные меры содействия занятости» доступна программа «Специалист по аналитике и базам данных в информационных системах» — онлайн, обучение с нуля, официальный документ установленного образца, полностью за счёт государства. Смотрите каталог доступных программ.
Подайте заявку —
забронируйте место в группе
45 000 мест на 2026 год. Бесплатное обучение по федеральному проекту «Активные меры содействия занятости»
- Онлайн
- От 2 месяцев
- Бесплатно
- Диплом
